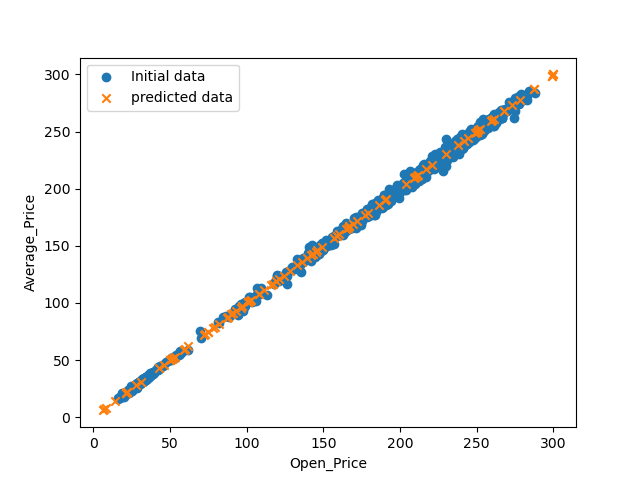
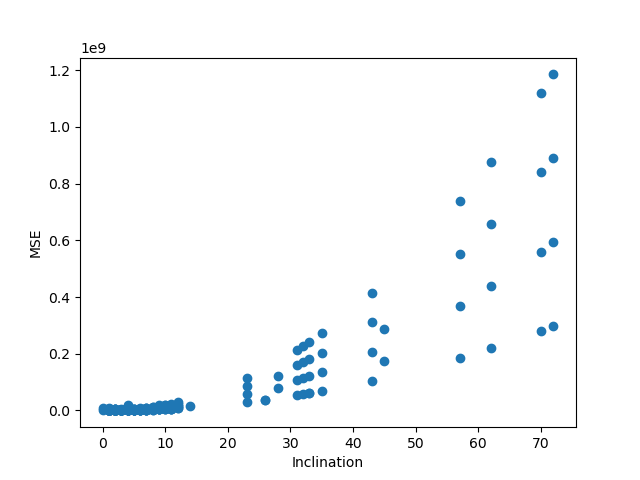
# ----------------주어진 데이터셋--------------------
f=open('Tesla.csv','r')rdr=csv.reader(f)arr=[]arr2=[]arr3=[]forlineinrdr:# Open
arr.append(float(line[1]))# High
arr2.append(float(line[2]))# Low
arr3.append(float(line[3]))# High와 Low의 평균값
avg=[]foriinrange(len(arr2)):av=(arr2[i]+arr3[i])/2avg.append(float(av))
초기 후보해 집합을 생성
먼저 초기 후보해 집합을 구한다.
Open가격 최소와 최대, 평균가격의 최소와 최대를 지정한다.
1
2
3
4
Openmin=2Openmax=300Avgmin=2Avgmax=300
4개의 값을 받아와 기울기 a의 값 4개를 얻는다.
1
2
3
# 초기 식 y = ax
defexpression(t,h):returnh/t
1
2
3
4
5
6
7
8
9
# 초기 a 4개 구하기
definit(Open1,Open2,Avg1,Avg2):a=[]foriinrange(4):OPEN=rn.randint(Open1,Open2)AVG=rn.randint(Avg1,Avg2)a.append(math.ceil(expression(OPEN,AVG)))returna
# 선택 연산
defselection(Aarr):ratio=[]foriinrange(4):ifi==0:ratio.append(Aarr[0]/sum(Aarr))else:ratio.append(ratio[i-1]+Aarr[i]/sum(Aarr))sx=[]foriinrange(4):p=rn.random()ifp<ratio[0]:sx.append(Aarr[0])elifp<ratio[1]:sx.append(Aarr[1])elifp<ratio[2]:sx.append(Aarr[2])else:sx.append(Aarr[3])returnsx
교차 연산
교차 연산을 하기 위해 선택연산에서 나온 값들을 이진수로 변경해 준다.
bin(x) 함수의 값은 “0b0100”이므로 0으로 대체해 준다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# bin() format
defbinformat(x):binformat='{0:>8}'.format(bin(x)).replace("b","0").replace("","0").replace("-","0")returnbinformat# int to binary
defint2Bin(str):binlist=[]foriinrange(4):binsrting=binformat(str[i])binlist.append(binsrting)returnbinlist