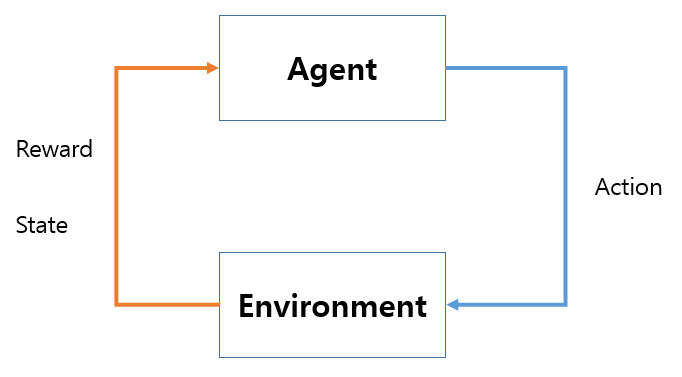
상태: 에이전트가 관찰 가능한 상태의 집합
행동: 에이전트가 상태에서 할 수 있는 행동의 집합
보상함수: 환경이 에이전트에게 주는 정보. 에이전트가 학습할 수 있는 정보
상태변환 확률: 에이전트가 어떠한 상태 s에서 행동 a를 해서 다음 상태 s’에 도달할 확률
감가율: 받는 보상정보를 수학적으로 표현하기 위함
반환값(return): 에이전트가 탐험하며 얻은 보상
Gt = Rt+1 + 𝛾Rt+2 + 𝛾2Rt+3 …
가치함수(value function): 얼마의 보상을 받을지에 대한 기댓값
v(s) = E[Gt|St = s] = E[Rt+1 + 𝛾Rt+2 + 𝛾2Rt+3 + … |St = s]
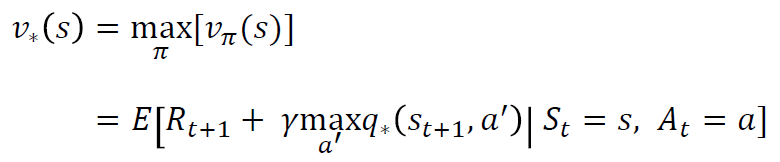
5*5인 그리드 월드에서의 가치함수가 구해지는 과정이다.
| itration | 가치함수(v𝜋) |
|---|---|
| 1 | v0(s1),…, v0(s25) |
| 2 | v1(s1),…, v1(s25) |
| … | … |
| k | v𝜋(s1),…, v𝜋(s25) |
정책 이터레이션 다이나믹 프로그래밍으로 벨만방정식을 풀어서 가치함수를 구하는 과정이다.
처음에는 무작위로 행동을 하고 iteration을 돌며 가치함수 최적화를 한다.
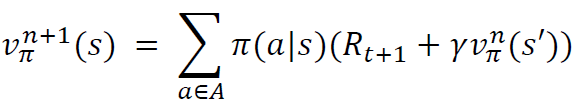
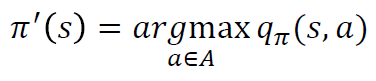
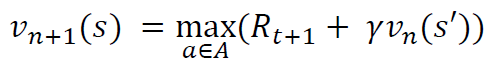
원의 넓이를 구하는 공식을 모를때 몬테카를로 근사를 사용할 수 있다.
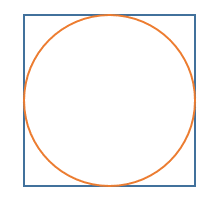
몬테카를로 근사로 원의 넓이 구하기
1 원이 그려진 종이위에 점을 무작위로 뿌린다.
2 뿌린 점들중 원에 들어간 점의 비율을 구하면 이미 알고있는 사각형의 넓이를 통해 원의 넓이를 추정할 수 있다.
3 뿌린 점의 비율로 (원의 넓이)/(사각형의 넓이) 를 근사하는 것이다.
파이썬으로 PI값 예측하기
다음 스텝의 보상과 가치함수를 샘플링하여 현재 상태의 가치함수를 업데이트한다.
V(St) <- V(St) + α(R + 𝛾V(St+1 - V(St)
R + 𝛾V(St+1)를 시간차 에러(Temporal difference error)라고 한다.
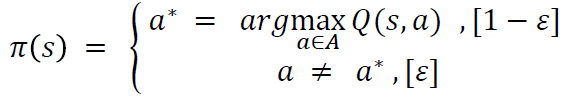
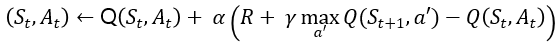
TAVE 6기가 8월부터 시작되었다. 머신러닝을 공부하려고 들어왔지만, 강화학습이 너무 재미있어보여서 강화학습스터디에 참여하게 되었다. 첫 스터디는 조장님이 쭉 설명을 해주셨다. 수식도 많고 헷갈리는 부분이 많았지만 반복해서 보다보니 이해가 잘 되었다.
같은 팀원들이 관심도 많고 잘하는 사람들이 많아 더 열심히 해야될것 같다.
우리 스터디 블로그이다.: TAVE 6기 강화학습 스터디 블로그