$dg(x)$가 약분이 되면서 아래 식처럼 되는것을 확인할 수 있다.
\begin{align} \Delta y={dy / dx} \Delta x \end{align}

z에 대한 y의 미분은 x에 대한 g(x)의 편미분들의 합이 된다.
\begin{align} y = f(g(x)) \end{align}
\begin{align} {dy / dx} = {df / dg(x)} {dg(x) / dx} \end{align}
$z = g(x)$, $y = f(z)$라고 가정한다면
\begin{align} \Delta z = {dg(x) / dx} \Delta x \end{align}
\begin{align} \Delta y= {df / dz} \Delta z= {df / dg(x)} {dg(x) / dx} \Delta x \end{align}
$dg(x)$가 약분이 되면서 아래 식처럼 되는것을 확인할 수 있다.
\begin{align} \Delta y={dy / dx} \Delta x \end{align}
z에 대한 y의 미분은 x에 대한 g(x)의 편미분들의 합이 된다.
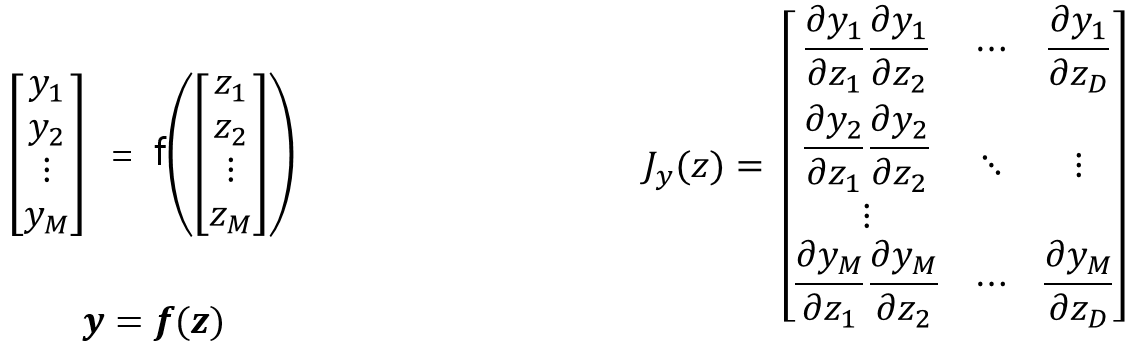
\begin{align} \Delta y = J_y (z) \Delta z \end{align}
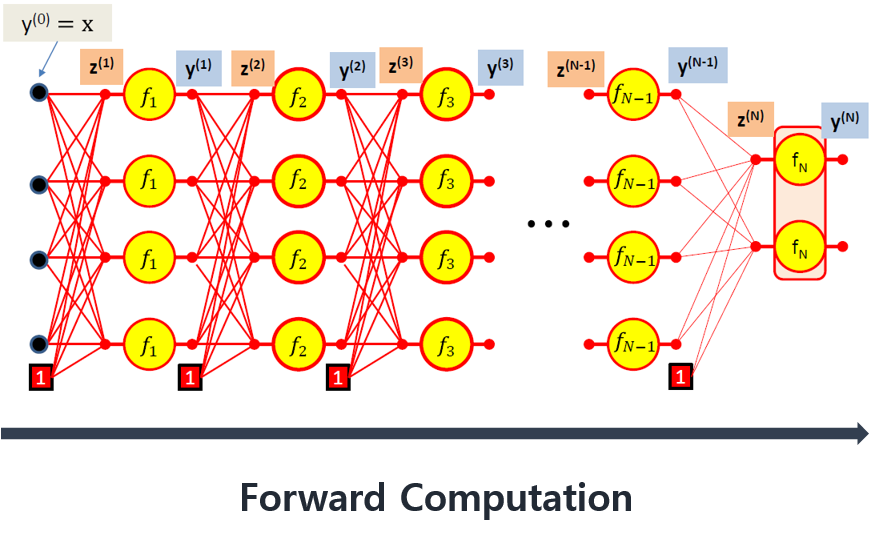
\begin{align} {z_j}^{(n)} = {\sum}_i {w_{ij}}^{(N)}{y_i}^{(N-1)} \end{align}
\begin{align} {y_j}^{(N)} = f_{N({z_j}^{(N)})} \end{align}
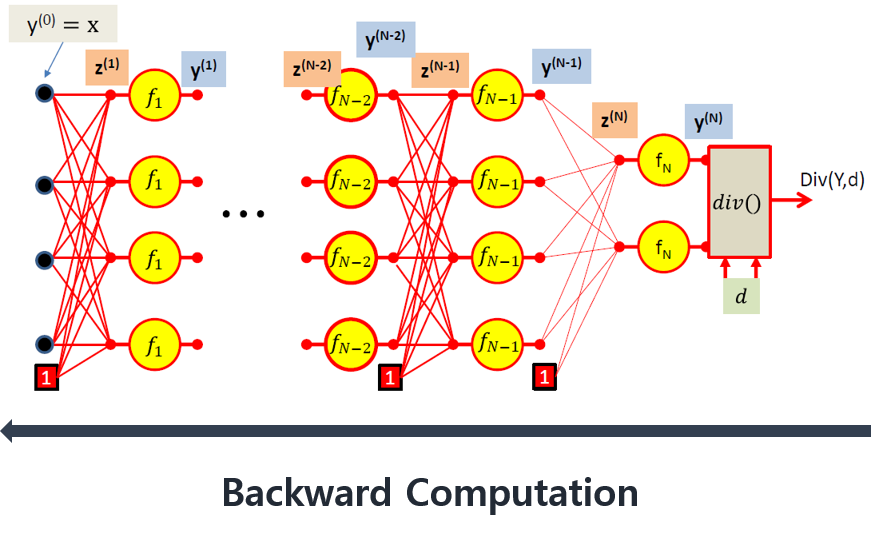
역전파의 시작은 divergence(Div)를 미분하는것으로 시작한다. \begin{align} \color{orange}{\partial Div(Y,d) / \partial {y_i}^{(N)}} \color{black}= \partial Div(Y,d)/\partial y_i \end{align}
Output layer 부분에서 y에 대한 divergence의 편미분은 단순한 미분형태이다.
\begin{align} \color{black}\partial Div/\partial {z_1}^{(N)} = \color{blue}\partial {y_1}^{(N)}/\partial {z_i}^{(N)}\color{black}* \color{orange}{\partial Div / \partial {y_i}^{(N)}} \end{align}
\begin{align} \color{blue}\partial {y_1}^{(N)}/\partial {z_i}^{(N)} \color{black}= {f_N}’({z_1}^{(N)}) \end{align}
\begin{align} \color{red}\partial Div/\partial {z_1}^{(N)}={f_N}’({z_1}^{(N)})*\partial Div / \partial {y_i}^{(N)} \end{align}
\begin{align} \color{black}\partial Div/\partial {w}_{11^{(N)}} = \color{orange}\partial {w_{11}}^{(N)}/\partial {z_1}^{(N)}\color{black}* \color{blue}{\partial Div / \partial {z_1}^{(N)}} \end{align}
\begin{align} \color{orange}\partial {w_{11}}^{(N)}/\partial {z_1}^{(N)} \color{black}={y_1}^{(N-1)} \end{align}
\begin{align} \color{red}\partial Div/\partial {w_{11}}^{(N)} = {y_1}^{(N-1)}* \partial Div / \partial {z_1}^{(N)} \end{align}
\begin{align} \partial Div/\partial {y_{1}}^{(N-1)} = {\sum}_i {\color{orange}\partial {z_{j}}^{(N)}/\partial {y_1}^{(N-1)} \color{black}* \color{blue}\partial Div/\partial {z_j}^{(N)}} \end{align}
\begin{align} \color{orange}\color{orange}\partial {z_{j}}^{(N)}/\partial {y_1}^{(N-1)} \color{black}={w}_{1j^{(N)}} \end{align}
\begin{align} \color{red}\partial Div/\partial {y_{1}}^{(N-1)} = {\sum}_i {w}_{1j^{(N)}}*\partial Div/\partial {z_j}^{(N)} \end{align}
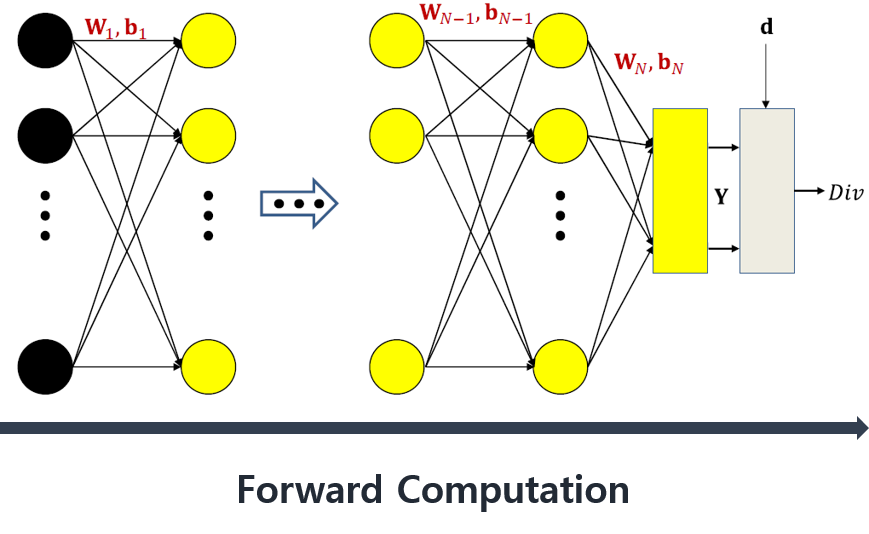
\begin{align} z_k = W_k {y}_{k-1} + b_k \end{align}
\begin{align} y_k = f_k(z_k) \end{align}
\begin{align} Y = {f}_N(W_N{f}_{N-1}(…f_2(W_2f_1(W_1x+b_1)+b_2)…+b_N) \end{align}
\begin{align} \color{blue}{\nabla _YDiv} \end{align}
\begin{align} \nabla_{z_N}Div = \color{blue}{\nabla_YDiv}\color{orange}{\nabla_{z_N}Y} \end{align}
\begin{align} \color{orange}{\nabla_{z_N}Y }\color{black}= J_Y(Z_N) \end{align}
\begin{align} \color{red}{\nabla_{z_N}Div = {\nabla_YDiv}J_Y(Z_N)} \end{align}
\begin{align} \nabla_{y_{N-1}}Div = \color{blue}{\nabla_z{_N}Div}\color{black}*\color{orange}{\nabla_{y{_N-1}}Z_N} \end{align}
\begin{align} \color{orange}{\nabla_{y_{N-1}}Z_N }\color{black}= W_N \end{align}
\begin{align} \color{red}{\nabla_{y_{N-1}}Div = \nabla_z{_N}Div*W_N} \end{align}
\begin{align} \nabla_{w_{k}}Div = y_{k-1}* \nabla_{z_{k}}Div \end{align}
\begin{align} \nabla_{b_{k}}Div = \nabla_{z_{k}}Div \end{align}
DO:
$Loss = 0$
For all k, initialize $\nabla_{w_k}Loss = 0, \nabla_{b_k}Loss = 0$
For all t = 1:T
Forward propagation:
Output$Y(X_t$)
Divergence $Div(Y_t,d_t)$
$Loss +=Div(Y_t, d_t)$
Backward propagation
$\nabla_{y_{k}}Div = {\nabla_{Z_{k+1}}Div}W_{k+1}$
$\nabla_{z_{k}}Div = {\nabla_{y_{k}}Div}J_{y_k}(z_k)$
$\nabla_{w_k}Div = y_{k-1}\nabla_{z_k}Div$
$\nabla_{b_k}Div = \nabla_{z_k}Div$
$\nabla_{W_k}Loss +=\nabla_{w_k}Div$
$\nabla_{b_k}Loss +=\nabla_{b_k}Div$
For all k, update:
$W_k = W_k {-{\eta / T}(\nabla_{W_k}Loss)^T}$
$b_k = b_k {-{\eta / T}(\nabla_{W_k}Loss)^T}$