Generative Adversarial Networks
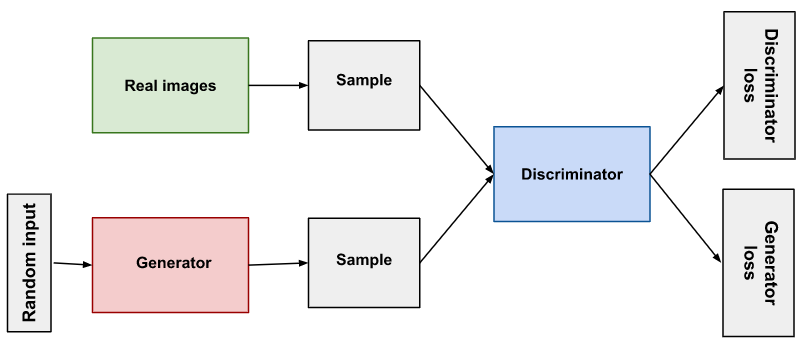
- GAN은 두 가지의 모델을 적대적(Adversarial)으로 경쟁을 시키면서 발전시키는 것이다.
- Generator는 그럴듯한 가짜 이미지를 생성하여 Discriminator를 속이는 것이다.
- Discriminator는 Generator가 생성한 가짜 이미지와 진짜 이미지를 구분하는 것이다.
이미지 출처:developers
Train
Objective function
\begin{align}
minmax{(_{\theta{_g}}, _{\theta{_d}})} = [E{_{x} \sim P{_{data}}} \log D{_{\theta}{_d}} (x) + E{_{z} \sim p{_{z}}} \log (1 - D{_{\theta}{_d}} (G{_{\theta}{_g}} (z))) ]
\end{align}
-
Gradient ascent on discriminator
- 판별자는 $\theta_d$를 최대화 하는 방향으로 학습을 진행한다.
\begin{align}
max{(_{\theta{_d}})} = [E{_{x} \sim P{_{data}}} \log D{_{\theta}{_d}} (x) + E{_{z} \sim p{_{z}}} \log (1 - D{_{\theta}{_d}} (G{_{\theta}{_g}} (z))) ]
\end{align}
-
Gradient descent on generator
GAN 구현(Tensorflow)
- GAN을 tensorflow를 사용하여 구현하였다.
- 전체 코드는 여기에서 볼 수 있다.
Generator
- Fully connected layer인 Dense layer를 사용하였고 activation function은 relu를 사용하였다.
- 마지막 layer에서는 sigmoid를 사용하였고 출력의 크기를 조절해 줬다.
- 마지막 layer에서 tanh 함수를 사용하였을때는 학습이 잘 이뤄지지 않았다. 범위가 0부터 1인 sigmoid 함수를 사용하니 학습이 잘 이뤄졌다.
Discriminator
- 입력되는 이미지의 크기를 정해주었다.
- 각 layer마다 LeakyReLU 함수를 사용하였다.
Loss
- loss 함수는 Binary cross entropy를 사용하였다. 판별자가 출력한 loss가 정답에 가까우면 낮아지고 정답에서 멀면 커진다.
Optimizer
- optimizer는 생성자는 Adam을 사용하고, 판별자는 RMSProp을 사용하였다.
- 생성자와 판별자 모두 Adam을 사용했을때는 loss도 커지고 이미지 생성이 제대로 이뤄지지 않았다.
Train
- Generator loss와 Discriminator loss를 계산한다.
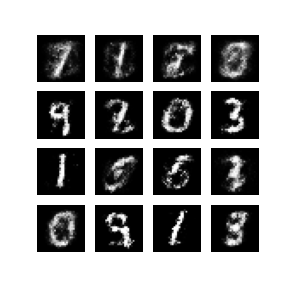
- Generator가 학습을 한 후 36번째 생성한 이미지이다. 완벽하진 않지만 50번 학습중 가장 잘 생성되었다.
References
쉽게 씌어진 GAN
Jaejun Yoo’s Playgraound