파이썬 알고리즘 인터뷰 6장을 정리한 내용입니다.
- 문자열을 변경하거나 분리하는 등의 여러 과정을 말한다
- 문자열 조작은 코테에서 상당히 빈번하게 출제됨
사용되는 분야
- 정보처리분야
- 통신 시스템 분야
- 프로그래밍 시스템 분야
유효한 팰린드롬(p.139)
- 주어진 문자열이 팰린드롬인지 확인하라
- 대소문자를 구분하지 않으며 영문자와 숫자만을 대상으로 한다
- 팰린드롬은 회문이다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 팰린드롬은 회문이다
a = input()
def palindrome(s: str) -> bool:
strs = []
for char in s:
if char.isalnum():
strs.append(char.lower())
while len(strs) > 1:
if strs.pop(0) != strs.pop():
return False
return True
print(palindrome(a))
- isalnum은 영문자, 숫자 여부를 판별하는 함수다
- char 의 isalnum이 True면 strs 리스트에 lower()을 하여 추가 한다
- pop(0)은 맨 앞의 값을 가져올 수 있다
Deque()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# deque를 사용
import collections as col
from typing import Deque
def palindrome(s: str) -> bool:
strs: Deque = col.deque()
for char in s:
if char.isalnum():
strs.append(char.lower())
while len(strs) > 1:
if strs.popleft() != strs.pop():
return False
return True
a = input()
print(palindrome(a))
- Deque 자료형을 명시적으로 선언한 이용한 코드이다
- 명시적으로 선언하면 속도를 높일 수 있다
collection.deque() 에서 3, 4, 9순서로 append 한 후 popleft()를 하면 3 이 나옴
deque()에서 pop을 하면 9가 나온다.
슬라이싱
1
2
3
4
5
6
7
8
import re
def palindrome(s: str) -> bool:
s = s.lower()
s = re.sub('[^a-z0-9]', '', s)
return s == s[::-1]
- s[::-1]은 str형을 반대로 뒤집는다.
- re는 regular expression의 약어로 정규식 모듈이다
정규식 모듈에 관한 설명: https://wikidocs.net/4308
- 슬라이싱을 사용한 코드는 코드 길이도 줄어들고 내부적으로 c로 구현되어 속도가 좋다

슬라이싱은 상당히 빠르다
![/assets/img/posts/pyAlgo/chapter6/pic_2021-03-29_19-49-28.png]()
s[:]하면 둘 다 생략하면 사본을 리턴한다 문자열이나 리스트를 복사하는 파이썬다운 방식이다.
문자열 뒤집기(p.145)
- 문자열을 뒤집는 함수를 작성하라 입력값은 문자 배열이며 리턴 없이 리스트 내부를 직접 조작하라
입력 예시
hello
출력
[“o” “l” “l” “e” “h”]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# two pointer 사용
s = ["h", "e", "l", "l", "o"]
def rev_str(s: list) -> list:
empl = len(s) // 2 # 횟수
for i in range(empl):
# i = 0 tmp = 4
# i = 1 tmp = 3
tmp = s[i]
s[i] = s[len(s) - 1 - i]
s[len(s) - 1 - i] = tmp
return s
print(rev_str(s))
- two pointer를 사용하는 것에서 힌트를 얻음
- list는 가변 객체이기에 자릿수로 변경 가능하다
1
2
3
4
5
6
7
8
9
10
11
12
def rev_str(s: list) -> None:
left, right = 0, len(s) - 1
while left < right:
s[left], s[right] = s[right], s[left]
left = +1
right = -1
return s
# list 는 reverse를 사용할 수 있다
def rev_str_2(s: list) -> None:
s.reverse()
return s
- rev_str는 책의 two pointer 코드
- list는 가변 객체이며, reverse()함수를 사용 가능하기 때문에 간단하게 할 수 있다.
- s[::-1]을 사용하면 더 빠르게 풀 수 있지만, Leetcode에서는 공간 복잡도를 O(1)로 제한하여 오류가 난다
- s[:] = s[::-1]을 사용하면 동작한다
- 플랫폼에 대한 이해가 필요하다
로그 파일 재정렬(p.148)
로그파일을 재정렬 하는 기준
- 로그의 가장 앞 부분은 식별자이다
- 문자로 구성된 로그가 숫자 로그보다 앞에 온다
- 식별자는 순서에 영향을 끼치지 않지만, 문자가 동일할 경우 식별자 순으로 한다
- 숫자 로그는 입력 순서대로 한다
입력
logs = [“dig1 8 1 5 1”, “let1 art can”, “dig2 3 6”, “let2 own kit dig”, “let3 art zero”]
출력
[‘let1 art can’, ‘let3 art zero’, ‘let2 own kit dig’, ‘dig1 8 1 5 1’, ‘dig2 3 6’]
1
2
3
4
5
6
7
8
9
def log_reorder(logs: list) -> list:
letters, digits = [], []
for log in logs:
if log.split()[1].isdigit():
digits.append(log)
else:
letters.append(log)
letters.sort(key=lambda x: (x.split()[1:], x.split()[0]))
return letters + digits
- isdigit()은 숫자인지 여부를 판별해준다
람다 표현식
- 람다 표현식은 식별자 없이 실행 가능한 함수를 말한다.
- 함수 선언 없이 하나의 식으로 함수를 단순하게 표현 가능하다
가장 흔한 단어
- 금지된 단어를 제외한 가장 흔하게 등장하는 단어를 출력하라
- 대소문자 구분을 하지 않으며 구두점 또한 무시한다
입력
1
2
3
paragraph = "Bob hit a ball, the hit BALL flew far after it was hit."
banned = ["hit"]
출력
“ball”
데이터 전처리
- 문자에 대한 전처리를 하기위해 정규식을 섞어 처리한다
1
word = [word for word in re.sub(r'[^\w]', ' ', paragraph).lower().split() if word not in banned]
- \w는 단어 문자를 뜻하고 ^는 not을 뜻한다
- 위 코드의 의미는 단어 문자가 아닌 모든 문자를 공백으로 치환한다는 의미이다.
- 리스트 컴프리헨션 조건절에서는 banned를 제외한 단어가 저장이 된다.
1
2
3
4
5
6
# 내가 짠 코드
def most_common_word(s: str) -> str:
word = [word for word in re.sub(r'[^\w]', ' ', paragraph).lower().split() if word not in banned]
out = Counter(word).most_common(1)[0][0]
return out
- Leetcode에서는 collection을 기본적으로 지원하는것 같다 (파이참에서는 import collections를 해 줘야 함)
그룹 에너그램 - Leetcode #49
- 문자열 배열을 받아 애너그램 단위로 그룹핑 하라
- 애너그램은 언어유희로 문자를 재배열 하여 다른 뜻을 가진 단어로 바꾸는 것을 말한다
입력
[“eat”, “tea”, “tan”, “ate”, “nat”, “bat”]
출력
([[‘eat’, ‘tea’, ‘ate’],
[‘tan’, ‘nat’],
[‘bat’]])
1
2
3
4
5
6
def anagram(strs: list) -> list:
anagram = collections.defaultdict(list)
for word in strs:
anagram[''.join(sorted(word))].append(word)
return anagram.values()
- collections.defaultdict로 딕셔너리 객체를 만든다. (리스트 형태)
정렬 방법
sorted()
- 리스트와 숫자 문자 모두 정렬이 가능하다
1
2
3
b = 'kjhgkjhsagf'
print("".join(sorted(b))) # afgghhjjkks
- sorted로 정렬한 리스트를 문자로 결합하기위해 join을 사용했다
- sorted는 key=옵션을 지정해 정렬을 위한 키 또는 함수를 별도로 지정할 수 있다
1
2
3
c = ['cde', 'cfc', 'abc']
print(sorted(c, key=lambda x: (x[0], x[-1]))) # ['abc', 'cfc', 'cde']
- key는 함수를 지정하거나 lambda 표현식으로 사용해도 된다.
sort()
- sort는 리스트 자체를 정렬할 수 있다
- sort는 리스트를 덮어쓰기때문에 사요에 주의해야 한다
1
2
a_list.sort()
print(a_list)
가장 긴 팰린드롬 부분 문자열 - Leetcode #5 (p.159)
- 가장 긴 팰린드롬 부분 문자열을 출력하라
입력
“babad”
출력
“bab” or “aba”
투 포인터의 이동
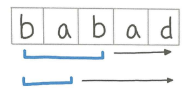
- 2칸과 3칸의 포인터가 슬라이딩 윈도우 처럼 이동한다
- 윈도우에 들어있는 문자열이 팰린드롬이면 이동을 멈추고 포인터를 확장하게 된다
- 2칸과 3칸을 이용하는 이유는 짝수(“bb”)와 홀수(“bab”)인 경우를 판별하기 위함이다
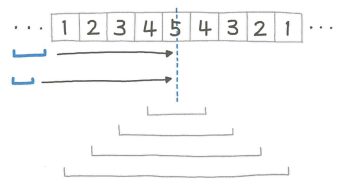
- 중앙을 중심으로 포인터를 확장하는 경우이다
- 두 개의 포인터들은 이동하다가 5에서 3칸 포인터가 “454”로 확장되어 멈추게 되고, 포인터 확장을 시작한다
- 3칸 포인터가 확장을 완료하게되면 “123454321”까지 확장된다
- 2칸 포인터는 팰린드롬이 아니므로 무시된다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def long_pal(s: str) -> str:
# ----------------expand------------------
# 팰린드롬 여부 판별, 윈도우 확장
def expand(left: int, right: int) -> str:
while left >= 0 and right <= len(s) and s[left] == s[right - 1]:
left -= 1
right += 1
return s[left + 1:right - 1]
# ----------------expand------------------
# 예외처리 - 길이가 2 미만, 전체 뒤집은 문자열이 같을 경우 반환
if len(s) < 2 or s == s[::-1]:
return s
result = ''
for i in range(len(s) - 1):
result = max(result, expand(i, i + 1), expand(i, i + 2), key=len)
return result
- 슬라이싱과 인덱스로 조회하는것은 서로 다르다
- s = ‘12345’일때 s[1:3]은 23이 나오지만 s[3]은 4가 나온다
- 슬라이싱은 n-1만큼 출력되고 인덱스 조회는 해당 인덱스의 값이 나온다
- expand() 함수는 홀수, 짝수 2개의 포인터가 팰린드롬 여부를 판별하면서 우측으로 이동하게 한다
- 판별한 값들중 최댓값이 최종 결과가 된다.
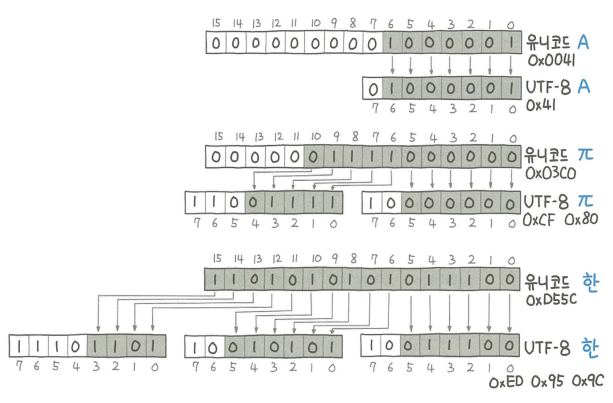
유니코드와 UTF-8
문자를 표현하는 대표적 방식으로 ASCII 인코딩 방식을 사용했다. 1바이트에 모든 문자를 표현했는데 그 중 1비트는 checksum으로 제외해 7비트(128글자)로 문자를 표현했다.
한글과 한자의 경우 2개 이상의 특수 문자를 합쳐서 표현되기 때문에 문자가 깨지는 경우가 많았다고 한다.
유니코드의 사용으로 2~4바이트의 공간에 여유롭게 문자를 할당할 수 있게 되었다.
유니코드의 내부 구조

Python이라는 문자가 차지하는 메모리를 나타낸 그림이다- 각 문자당 1바이트로도 충분하기 때문에 3바이트가 빈 공간으로 낭비되는것을 볼 수 있다
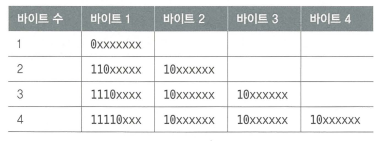
- 가장 많이 사용되는 인코딩 방식인
UTF-8의 바이트 순서의 이진 포맷이다 - 유니코드 값에 따라 가변적으로 바이트를 결정해 불필요한 공간 낭비를 줄일 수 있다
- 첫 바이트의 맨 앞 비트를 확인해
0인 경우 1바이트,10인 경우 특정 문자의 중간 바이트,110인 경우 2바이트로 문자 바이트의 길이를 확인할 수 있다
유니코드 문자의 UTF-8인코딩