
행 단위 데이터 추출하기
loc: 인덱스를 기준으로 행 데이터 추출iloc: 행 번호를 기준으로 행 데이터 추출
인덱스와 행 번호 개념
loc 속성으로 행 데이터 추출하기
1
2
3
4
5
6
7
country continent year
0 Afghanistan Asia 1952
1 Afghanistan Asia 1957
2 Afghanistan Asia 1962
3 Afghanistan Asia 1967
4 Afghanistan Asia 1972
- 왼쪽의 번호가 인덱스이다
- 실제 데이터 프레임에서는 확인할 수 없는 값이다
1
2
3
4
5
6
7
8
9
print(df.loc[0])
----------------
country Afghanistan
continent Asia
year 1952
lifeExp 28.801
pop 8425333
gdpPercap 779.445
Name: 0, dtype: object
loc을 사용하면 행 데이터를 추출할 수 있다loc[-1]을 사용하면 뒤에서 첫 번째 데이터를 보여주지 않고 오류가 난다- 마지막 행 데이터를 추출하려면 데이터의 shape을 알아야 한다
1
2
3
4
5
6
7
8
print(df.tail(n=1))
print(df.loc[[0, 99, 999]])
----------------------------
country continent year lifeExp pop gdpPercap
0 Afghanistan Asia 1952 28.801 8425333 779.445314
99 Bangladesh Asia 1967 43.453 62821884 721.186086
999 Mongolia Asia 1967 51.253 1149500 1226.041130
tail(n=1)을 사용하면 마지막 데이터를 알 수 있다loc[[0, 99, 999]]을 사용하면 원하는 인덱스 데이터를 알 수 있다
tail 과 loc 속성이 반환하는 자료형은 다르다
1
2
3
4
5
sub_loc = df.loc[0]
sub_tail = df.tail(n=1)
-----------------------
<class 'pandas.core.series.Series'>
<class 'pandas.core.frame.DataFrame'>
loc이 반환하는 자료형은Series이고tail이 반환하는 자료형은DataFrame이다
iloc 속성으로 행 데이터 추출하기
1
2
3
4
5
6
7
8
9
print(df.iloc[1])
------------------
country Afghanistan
continent Asia
year 1957
lifeExp 30.332
pop 9240934
gdpPercap 820.853
Name: 1, dtype: object
iloc속성으로 행 데이터를 추출할 수 있다loc속성은 데이터 프레임의 인덱스를 사용해서 추출했지만,iloc속성은 데이터 순서를 의미하는 행 번호를 사용하여 데이터를 추출한다loc속성과는 다르게df.iloc[-1]로 마지막 데이터를 추출할 수 있다- 여러 행을 추출하는 것은
loc과 동일하게iloc[[0, 99, 999]]로 사용하면 된다
슬라이싱과 range 메서드
1
2
3
4
5
6
7
8
sub_sli = df.loc[:, ['year', 'pop']]
------------------------------------
year pop
0 1952 8425333
1 1957 9240934
2 1962 10267083
3 1967 11537966
4 1972 13079460
- 모든 행에 대해
year과pop열을 추출하는 방법이다
1
2
3
4
5
6
7
8
9
sub_range = df.iloc[:, list(range(5))]
print(sub_sli.head())
--------------------------------------
country continent year lifeExp pop
0 Afghanistan Asia 1952 28.801 8425333
1 Afghanistan Asia 1957 30.332 9240934
2 Afghanistan Asia 1962 31.997 10267083
3 Afghanistan Asia 1967 34.020 11537966
4 Afghanistan Asia 1972 36.088 13079460
- 모든 행의 5번째 열까지 출력을 한다
df.iloc[:, list(range(3))]와df.iloc[:, :3]의 결과는 동일하다- 큰 규모의 데이터 분석에서는
loc속성이 유리하다
기초적인 통계 계산하기
그룹화한 데이터의 평균 구하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
grouped_year_df = df.groupby('year')
lifeExp = grouped_year_df['lifeExp']
print(lifeExp.mean())
------------------------------------
year
1952 49.057620
1957 51.507401
1962 53.609249
1967 55.678290
1972 57.647386
1977 59.570157
1982 61.533197
1987 63.212613
1992 64.160338
1997 65.014676
2002 65.694923
2007 67.007423
Name: lifeExp, dtype: float64
groupby()로 속성끼리 묶어서 데이터를 확인할 수 있다- 위 코드는 연도별로 그룹화한
lifeExp열을 얻을 수 있다 mean()메서드를 사용해 평균값을 알 수 있다
1
2
3
4
5
6
7
8
9
unique = df.groupby('continent')['country'].nunique()
-----------------------------------------------------
continent
Africa 52
Americas 25
Asia 33
Europe 30
Oceania 2
Name: country, dtype: int64
nunique()를 사용하면 빈도수를 알 수 있다
그래프 그리기
1
2
3
global_year_lifeExp = df.groupby('year')['lifeExp'].mean()
print(global_year_lifeExp.plot())
plt.show()
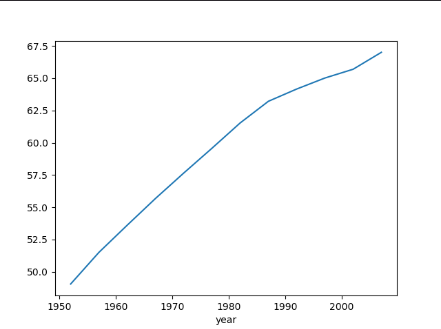
plot()메서드를 사용해서 그래프를 그릴 수 있다