
비지도 학습
지도 학습은 레이블된 데이터를 이용해 학습을 진행한다. 데이터에 정답이 있는 경우이다. 이번 장에서는 데이터에 레이블을 붙일 필요 없이 알고리즘이 레이블이 없는 데이터를 바로 사용할 수 있는 비지도 학습에 대해 알아본다.
비지도 학습에는 군집(clustering), 이상치 탐지(outlier detection), 밀도 추정(density estimation)이 있다.
군집
군집은 비슷한 샘플을 구별해 하나의 클러스터 또는 비슷한 샘플의 그룹으로 할당하는 작업이다. 비지도 학습 중 하나인 군집을 알아보기 위해 붓꽃 데이터 셋으로 알아볼 것이다.
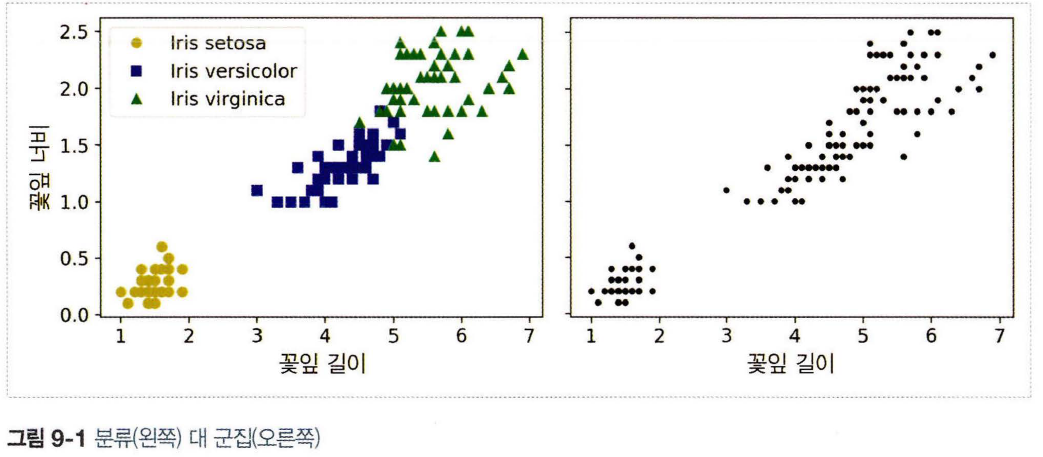
위 그래프는 각 꽃잎의 너비와 길이를 분류와 군집을 비교한 것이다. 왼쪽 그래프는 레이블이 있는 데이터로 각 붓꽃의 품종(클래스)이 잘 분류되어 있다. 오른쪽 그래프는 레이블이 없어 분류 알고리즘을 사용하지 못한다.
clustering은 고객 분류, 데이터 분석, 차원 축소 기법, 이상치 탐지, 준지도 학습, 검색 엔진, 이미지 분할에 사용된다. 잘 알려진 clustering 알고리즘인 k-means와 DBSCAN을 알아보자.
K-Means(k-평균)
k-평균 알고리즘은 반복을 통해 빠르고 효율적인 clustering이 가능하게 해주는 알고리즘이다.
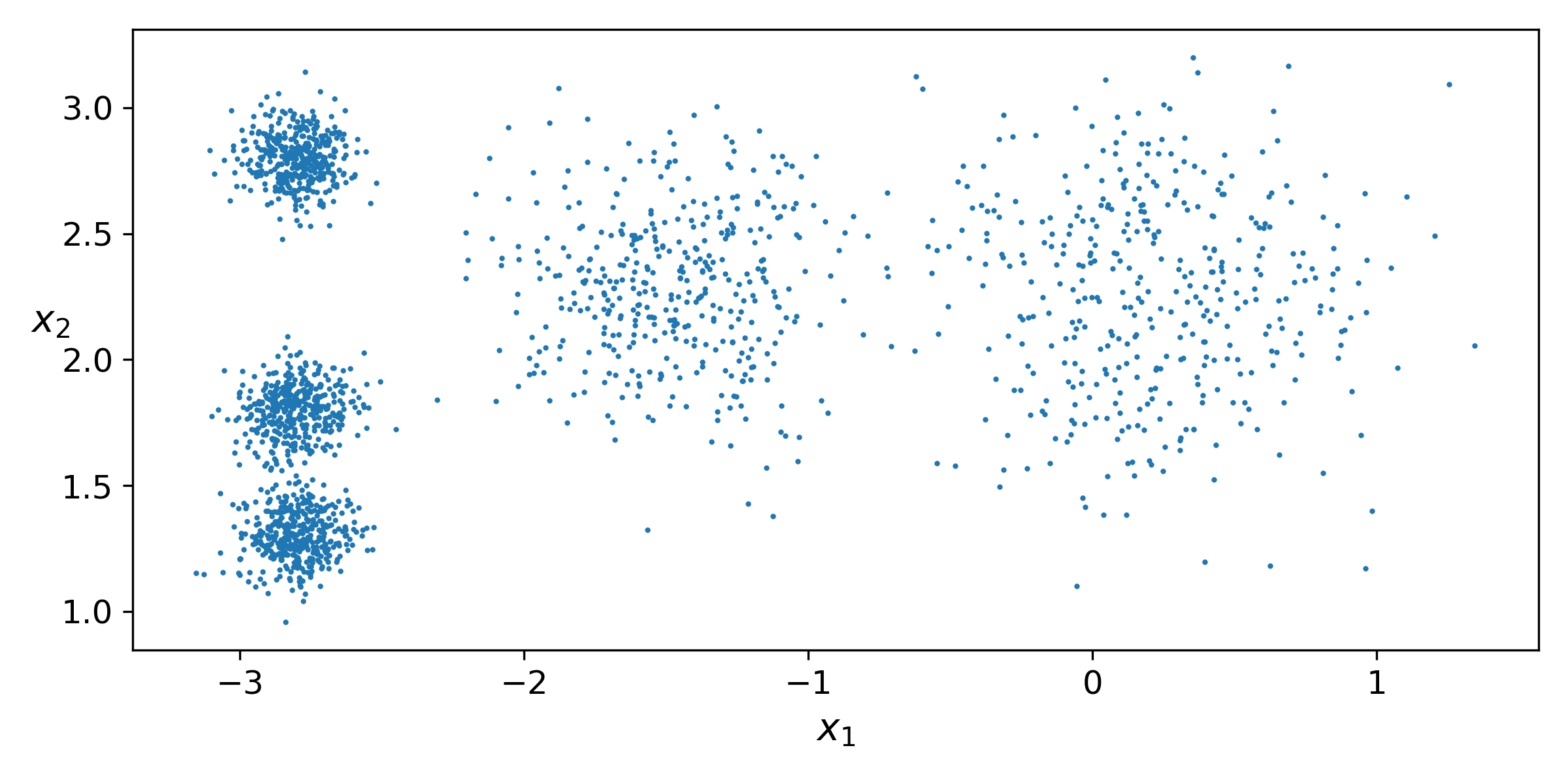
샘플 덩어리 다섯 개로 이루어진 레이블이 없는 데이터 셋이다. 이 샘플 데이터에 k-means 알고리즘을 이용해 clustering을 해 볼 것이다.
1
2
3
4
5
from sklearn.cluster import KMeans
k = 5
kmeans = KMeans(n_clusters=k, random_state=42)
y_pred = kmeans.fit_predict(X)
k-means 알고리즘에서는 찾을 cluster의 개수 k를 지정해 줘야 한다. fit_predict로 클러스터를 구분한다.
1
2
3
4
5
6
7
8
9
>>> y_pred
array([4, 0, 1, ..., 2, 1, 0], dtype=int32)
>>> kmeans.cluster_centers_
array([[-2.80389616, 1.80117999],
[ 0.20876306, 2.25551336],
[-2.79290307, 2.79641063],
[-1.46679593, 2.28585348],
[-2.80037642, 1.30082566]])
y_pred는 각 샘플에 할당된 다섯 개의 클러스터의 인덱스 중 하나의 값을 가진다. cluster_centers_를 출력해 보면 각 클러스터의 중심 값을 얻을 수 있다.
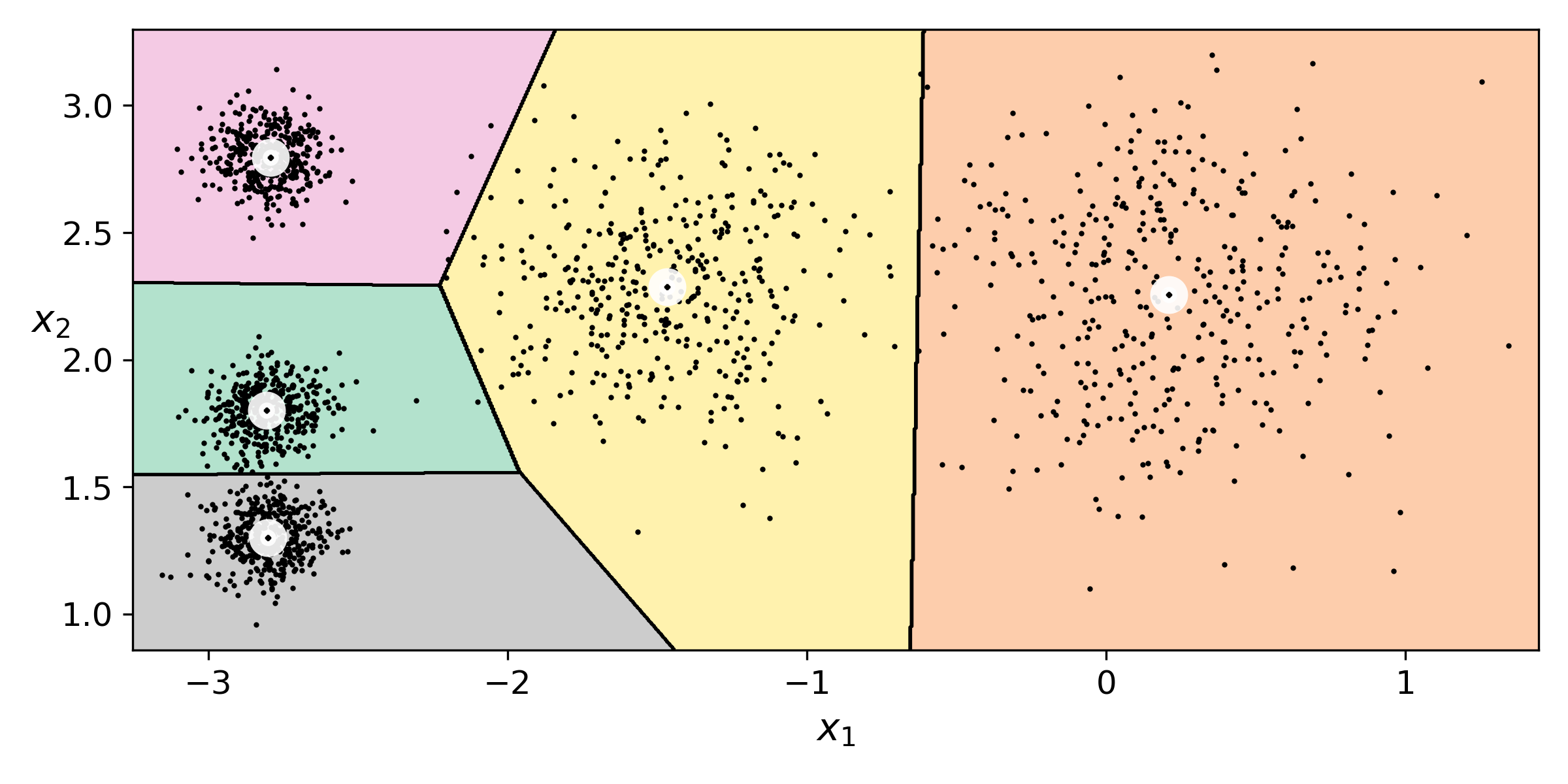
k-means의 결정 경계를 보여주는 보로노이 다이어그램이다. 대부분의 샘플들이 알맞은 레이블이 부여되었지만, 일부는 잘못 부여된 것을 볼 수 있다. 이처럼 샘플을 하나의 클러스터에 할당하는 것을 hard clustering이라고 한다.
Soft Clustering(소프트 군집)
Soft clustering은 클러스터마다 샘플에 점수를 부여하는 방법이다. 점수는 샘플과 센트로이드 사이의 거리가 될 수 있다.
1
2
3
4
5
>>> kmeans.transform(X_new)
array([[2.81093633, 0.32995317, 2.9042344 , 1.49439034, 2.88633901],
[5.80730058, 2.80290755, 5.84739223, 4.4759332 , 5.84236351],
[1.21475352, 3.29399768, 0.29040966, 1.69136631, 1.71086031],
[0.72581411, 3.21806371, 0.36159148, 1.54808703, 1.21567622]])
transform()은 KMeans클래스의 메서드로 샘플과 센트로이드 사이의 거리를 반환해 준다. 첫 번째 샘플은 첫 번째 센트로이드와 거리가 2.81이 되는 것을 알 수 있다.
K-Means 알고리즘의 동작
- 군집의 개수
k지정 - 초기 중심점 설정
- 샘플을 군집에 할당
- 중심점 재설정
- 샘플을 군집에 재할당
- 중심점의 위치가 더 이상 변하지 않을 때까지 중심점 재설정으로 돌아간다.
센트로이드 초기화 방법
1
2
3
4
good_init = np.array([[-3, 3], [-3, 2], [-3, 1], [-1, 2], [0, 2]])
kmeans = KMeans(n_clusters=5, init=good_init, n_init=1, random_state=42)
kmeans.fit(X)
kmeans.inertia_
센트로이드 값들을 근사하게 알 수 있는 경우 KMeans의 init매개변수로 센트로이드 리스트를 사용한다.
다른 방법으로 랜덤 초기화를 다르게 하여 여러 번 알고리즘을 실행한 다음 가장 좋은 솔루션을 선택하는 것이다. 랜덤 초기화 횟수는 n_init매개변수를 사용한다. 최적의 솔루션은 샘플과 가장 가까운 센트로이드 사이의 평균 제곱 거리가 기준이며 모델의 inertia(이너셔)라고 한다. inertia_로 이너셔의 값을 알 수 있으며, 이너셔의 값이 가장 작은 솔루션이 반환된다.
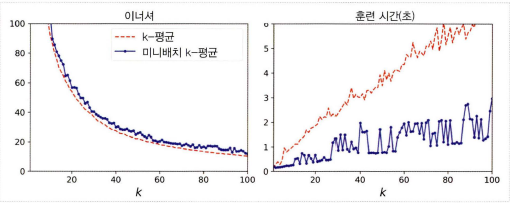
Minibatch K-Means
전체 데이터 셋을 사용해 반복하지 않고 각 반복마다 미니배치를 사용해 센트로이드를 조금씩 움직인다. 메모리에 들어가지 않는 대량의 데이터셋에 클러스터링을 적용할 수 있는 것이 장점이다.
1
2
3
4
from sklearn.cluster import MiniBatchKMeans
minibatch_kmeans = MiniBatchKMeans(n_clusters=5, random_state=42)
minibatch_kmeans.fit(X)
최적의 클러스터 개수 찾기
최적의 클러스터 개수를 찾기 위해서는 가장 작은 이너셔를 가지는 모델을 선택하면 될 것 같지만, 이너셔는 k값이 증가하면 작아지기 때문에 최적의 k룰 찾기 좋은 방법은 아니다.
Elbow
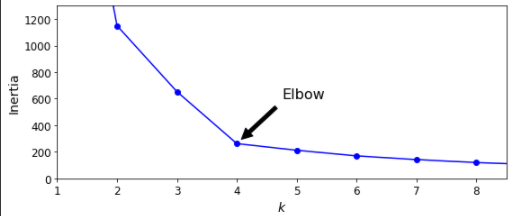
최적의 k값을 찾기 위해 Elbow를 사용한다. Elbow는 이너셔 그래프를 클러스터 개수 k의 함수로 그렸을 때 꺾이는 지점이다. 이 그래프에서 Elbow는 k가 4일 때를 가리키고 있고, Elbow로 알 수 있는 최적의 값이다.
실루엣 점수
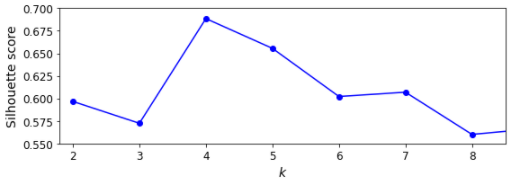
실루엣 점수로 최적의 k값을 찾을 수 있다. 실루엣 점수는 모든 샘플에 대한 실루엣 계수의 평균이다.
- a: 동일한 클러스터에 있는 다른 샘플까지 평균 거리
- b: 가장 가까운 클러스터까지 평균 거리
실루엣 계수는 -1부터 1까지의 값을 가지고 1에 가까운 값일수록 클러스터 안에 잘 속해 있다는 의미이고, 0에 가까우면 클러스터 경계에 위치한다는 것이고, -1에 가까우면 잘못된 클러스터에 할당되었다는 의미다.
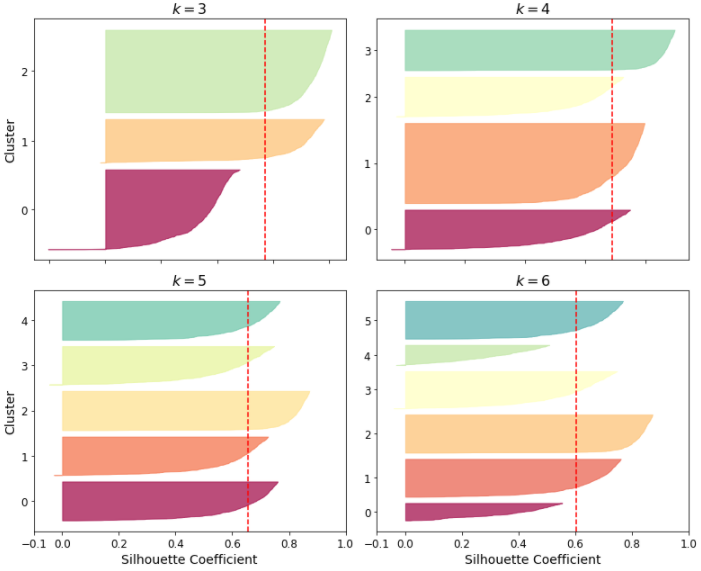
실루엣 다이어그램은 모든 샘플의 실루엣 계수를 할당된 클러스터와 계숫값으로 정렬한 그래프이다. 클러스터마다 칼 모양의 그래프가 그려지는데 높이는 클러스터가 포함하고 있는 샘플의 개수이고, 너비는 클러스터에 포함된 샘플의 정렬된 실루엣 계수를 나타낸다. 너비가 넓을수록 성능이 좋다고 판단한다.
군집을 이용한 이미지 분할
이미지 분할은 이미지를 segment 여러개로 분할하는 작업이다. semantic 분할에서는 동일한 종류의 물체에 속한 모든 픽셀은 같은 세그먼트에 할당된다.

위 이미지는 색상 클러스터 개수에 따른 k-means를 사용해 만든 이미지 분할이다.
군집을 사용한 전처리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X_digits, y_digits = load_digits(return_X_y=True)
# 훈련 세트와 테스트 세트로 나누기
X_train, X_test, y_train, y_test = train_test_split(X_digits, y_digits, random_state=42)
# 로지스틱 회귀 모델 훈련, 테스트 세트에서 평가
log_reg = LogisticRegression(multi_class="ovr", solver="lbfgs", max_iter=5000, random_state=42)
log_reg.fit(X_train, y_train)
log_reg_score = log_reg.score(X_test, y_test)
log_reg_score # 0.9688888888888889
1
2
3
4
5
6
7
8
9
10
11
from sklearn.pipeline import Pipeline
# 로지스틱 회귀 파이프라인 - kmeans 전처리 추가
pipeline = Pipeline([
("kmeans", KMeans(n_clusters=50, random_state=42)),
("log_reg", LogisticRegression(multi_class="ovr", solver="lbfgs", max_iter=5000, random_state=42)),
])
pipeline.fit(X_train, y_train)
pipeline_score = pipeline.score(X_test, y_test)
pipeline_score # 0.9777777777777777
1
2
3
4
5
6
7
from sklearn.model_selection import GridSearchCV
param_grid = dict(kmeans__n_clusters=range(2, 100))
grid_clf = GridSearchCV(pipeline, param_grid, cv=3, verbose=2)
grid_clf.fit(X_train, y_train)
grid_clf.score(X_test, y_test) # 0.9777777777777777
k-means를 전처리 단계에 사용해 로지스틱 회귀 모델을 적용한다. Mnist 데이터 셋을 사용하는데 클러스터 개수를 50개로 지정한 이유는 숫자를 쓴 방식이 모두 다르기 때문에 레이블 개수인 10개로 클러스터를 지정하는것은 좋지 않기 때문이다.
GridSearchCV를 사용해 최적의 클러스터를 찾고 파이프라인에 적용하면 더 좋은 성능이 나온다.
군집을 사용한 준지도 학습
1
2
3
4
5
n_labeled = 50
log_reg = LogisticRegression(multi_class="ovr", solver="lbfgs", random_state=42)
log_reg.fit(X_train[:n_labeled], y_train[:n_labeled])
log_reg.score(X_test, y_test) # 0.8333333333333334
레이블이 없는 샘플이 많고 레이블이 있는 샘플이 적을 때 사용하는 준지도 학습에도 군집을 사용할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
k = 50
kmeans = KMeans(n_clusters=k, random_state=42)
X_digits_dist = kmeans.fit_transform(X_train)
representative_digit_idx = np.argmin(X_digits_dist, axis=0)
X_representative_digits = X_train[representative_digit_idx]
y_representative_digits = np.array(
[4, 8, 0, 6, 8, 3, 7, 7, 9, 2, 5, 5, 8, 5, 2, 1, 2, 9, 6, 1, 1, 6,
9, 0, 8, 3, 0, 7, 4, 1, 6, 5, 2, 4, 1, 8, 6, 3, 9, 2, 4, 2, 9, 4,
7, 6, 2, 3, 1, 1])
log_reg = LogisticRegression(multi_class="ovr", solver="lbfgs", max_iter=5000, random_state=42)
log_reg.fit(X_representative_digits, y_representative_digits)
log_reg.score(X_test, y_test) # 0.09555555555555556

클러스터 개수를 50개로 지정하고 각 클러스터에서 센트로이드에 가장 가까운 이미지를 찾아 레이블을 수동으로 할당한다. 할당된 레이블로 훈련하게 되면 성능이 더 올라간 것을 볼 수 있다.
레이블을 동일한 클러스터에 있는 모든 샘플에 전파하는 레이블 전파를 사용하면 더 높은 성능을 얻을 수 있다.
DBSCAN
- 알고리즘이 각 샘플에서 작은 거리인 $\epsilon$내에 샘플이 몇 개 놓여 있는지 세고 이 지역을 샘플의 $
\epsilon-이웃$이라고 부른다. - 자기 자신을 포함한 $
\epsilon-이웃$내에 적어도min_samples개 샘플이 있다면 이를핵심 샘플로 간주한다. 핵심 샘플의 이웃에 있는 모든 샘플은 동일한 클러스터에 속한다. 이웃에는 다른핵심 샘플이 포함될 수 있다.핵심 샘플의 이웃은 계속해서 하나의 클러스터를 형성한다.핵심 샘플이 아니고 이웃도 아닌 샘플은 이상치로 판단한다.
DBSCAN알고리즘은 모든 클러스터가 충분히 밀집되어 있고 밀집되지 않은 지역과 잘 구분될 때 좋은 성능을 낸다.
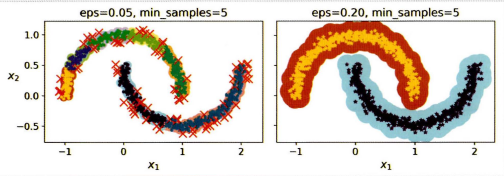
$\epsilon$의 값에 따른 그래프이다. $\epsilon$의 값이 0.05인 경우 클러스터를 개수는 7개로 나타나고 많은 샘플들을 이상치로 판단했다. $\epsilon$의 값이 0.2인 경우는 이상치가 없는 완벽한 군집을 갖게 된다.
가우시안 혼합 모델(GMM)
샘플이 파라미터가 알려지지 않은 여러 개의 혼합된 가우시안 분포에서 생성되었다고 가정하는 확률 모델이다. 하나의 가우시안 분포에서 생성된 모든 샘플은 하나의 클러스터를 생성한다.
1
2
3
4
from sklearn.mixture import GaussianMixture
gm = GaussianMixture(n_components=3, n_init=10, random_state=42)
gm.fit(X)
GaussianMixture를 사용해 주어진 데이터 X가 주어졌을 때 가중치 $\phi$와 전체 분포의 파라미터 $\mu^{(1)}$에서 $\mu^{(k)}$까지와 $\Sigma^{(1)}$에서 $\Sigma^{(k)}$까지를 추정한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
>>> gm.weights_
array([0.39025715, 0.40007391, 0.20966893])
>>> gm.means_
array([[ 0.05131611, 0.07521837],
[-1.40763156, 1.42708225],
[ 3.39893794, 1.05928897]])
>>> gm.covariances_
array([[[ 0.68799922, 0.79606357],
[ 0.79606357, 1.21236106]],
[[ 0.63479409, 0.72970799],
[ 0.72970799, 1.1610351 ]],
[[ 1.14833585, -0.03256179],
[-0.03256179, 0.95490931]]])
데이터를 생성하기 위해 사용한 가중치는 0.2, 0.4, 0.4이다. 이 클래스는 EM(Expectation-Maximization) 알고리즘을 사용한다. k-means와 비슷하게 클러스터 파라미터를 랜덤하게 초기화하고 수렴할 때까지 두 단계를 반복하게 된다.
- 현재 클러스터 센트로이드에 가장 가까운 데이터 셋을 할당한다. (Expectaion)
- 할당한 데이터들을 평균으로 클러스터의 중심을 다시 계산한다. (Maximization)
가우시안 혼합 모델은 생성모델이므로 새로운 샘플을 생성하는 것도 가능하다. 특성이나 클러스터가 많거나 샘플이 적을 경우 EM 알고리즘이 최적의 솔루션이 되기 어렵다. 이를 해결하기 위해 클러스터의 모양과 방향의 범위를 제한하는 것이 필요하다. 공분산 행렬에 제약을 추가하는 방법을 사용할 수 있다.
공분산 행렬 제약 조건
- full:
covariance_type의 기본값으로 각 클러스터의 모양, 크기, 방향에 제약이 없다. - spherical: 모든 클러스터가 원형이다. 지름은 다를 수 있다.(분산이 다르다)
- diag: 클러스터는 크기에 상관없이 어떤 타원형도 가능하다. 타원의 축은 좌표 축과 나란해야 한다.
- tied: 모든 클러스터가 동일한 타원모양, 크기, 방향을 가진다.
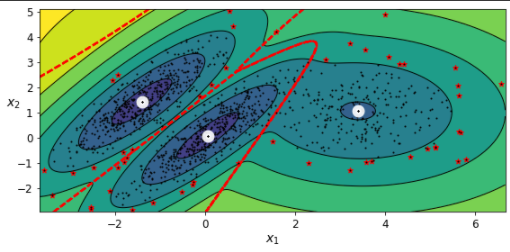
가우시안 혼합을 사용한 이상치 탐지
1
2
3
densities = gm.score_samples(X)
density_threshold = np.percentile(densities, 4)
anomalies = X[densities < density_threshold]
보통과 많이 다른 샘플을 감지하는 것이 이상치 탐지다. 부정 거래, 결함 있는 제품 검출 등에 사용된다. 가우시안 혼합 모델을 이상치 탐지에 사용하는 방법은 밀도가 낮은 지역에 있는 모든 샘플을 이상치로 판단하는 것이다.
가우시안 혼합 모델은 이상치를 포함해 모든 데이터에 맞추려고 하기 때문에 이상치를 제거한 후 정제된 데이터셋에서 다시 훈련하게 된다.
베이즈 가우시안 혼합 모델
1
2
3
4
from sklearn.mixture import BayesianGaussianMixture
bgm = BayesianGaussianMixture(n_components=10, n_init=10, random_state=42)
bgm.fit(X)
1
2
>>> np.round(bgm.weights_, 2)
array([0.4 , 0.21, 0.4 , 0. , 0. , 0. , 0. , 0. , 0. , 0. ])
BasianGaussianMixture클래스는 불필요한 클러스터의 가중치를 0에 가깝게 만든다. 클러스터 개수를 10개로 지정하고 모델을 학습한 결과 3개의 클러스터가 필요하다는 것을 확인할 수 있다. 이는 위에서 얻었던 결과와 동일하다.
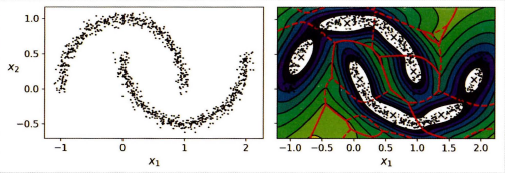
위 그래프는 반달 데이터셋에 BassianGaussianMixture를 적용한 것이다. 타원형 클러스터에 잘 동작하는 특징을 가졌기 때문에 밀도 추정은 가능하지만, 반달 모양 클러스터를 식별하는데에 실패했다.